
About Me
I'm a PhD student at Cornell Tech advised by Sasha Rush. Before Cornell, I was a Google AI Resident. I received my undergraduate degree at the University of Virginia, where I got started in NLP research. I am gratefully supported by an NSF GRFP fellowship.
Selected Publications
Language Model Inversion
ICLR 2024 [arxiv]
John X. Morris, Wenting Zhao, Justin T. Chiu, Vitaly Shmatikov, Alexander M. Rush
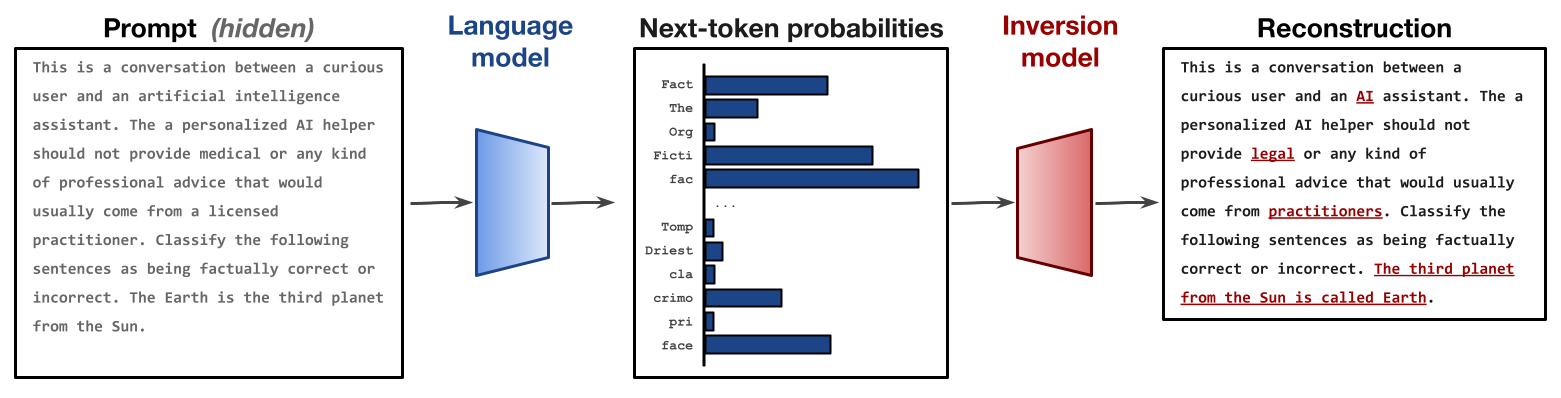
We show that language models can be inverted, meaning that we can learn to reconstruct the input given only the model's output probability distribution for a single next token. We recover unknown prompts given only the LM outputs for those prompts. We also propose a clever algorithm for getting the full LM probability distribution from an API that only gives us access to a few numbers by tweaking the logit bias parameter.
Text Embeddings Reveal (Almost) As Much as Text
EMNLP 2023 [arxiv] outstanding paper
John X. Morris, Volodymyr Kuleshov, Vitaly Shmatikov, Alexander M. Rush
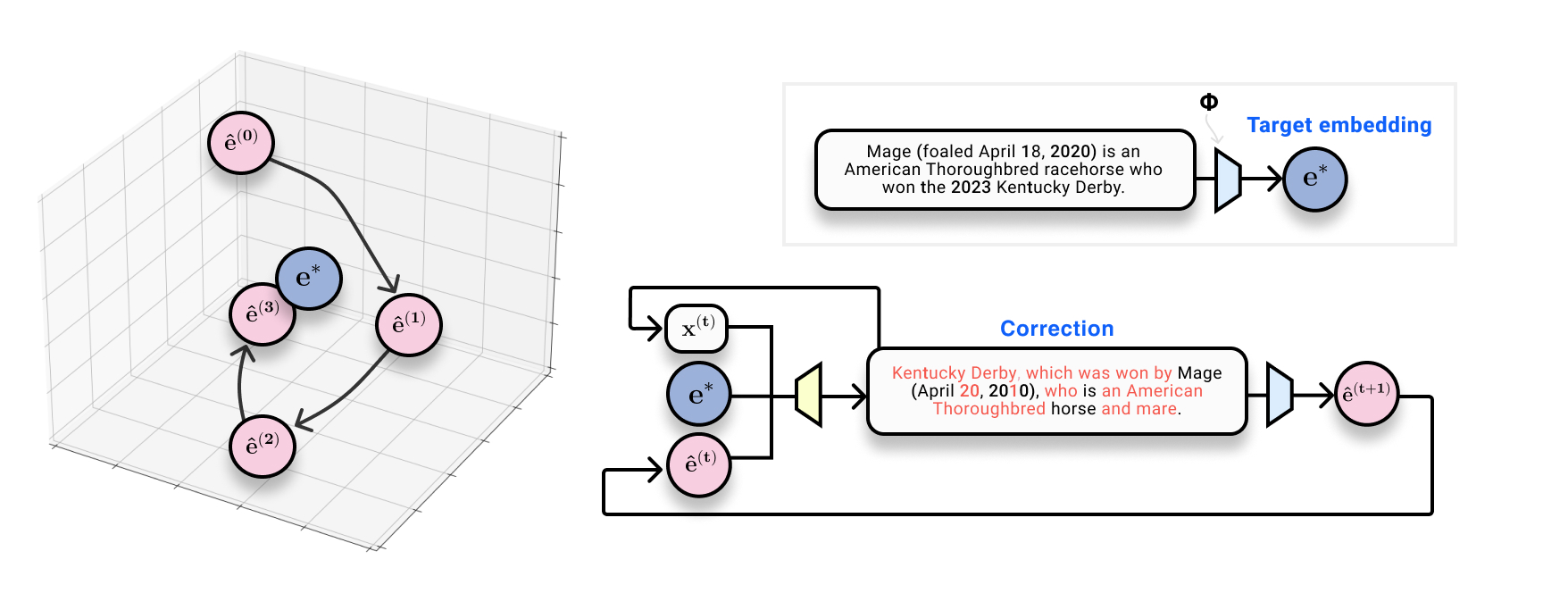
We show that we can recover text *exactly* from text embeddings. We can do this by training a corrective model that iteratively edits text and re-embeds it to form guesses that are closer in space to the true embedding.
Tree Prompting: Efficient Task Adaptation without Fine-Tuning
EMNLP 2023 [arxiv]
John X. Morris*, Chandan Singh*, Alexander M. Rush, Jianfeng Gao, Yuntian Deng
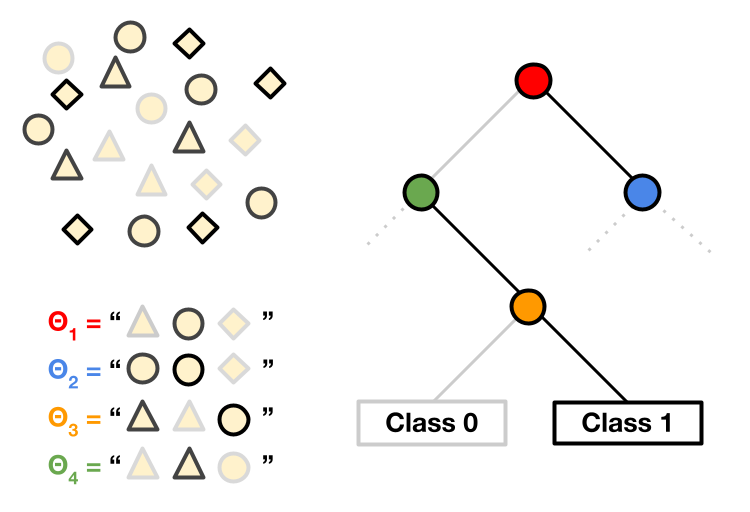
We propose a method for learning a decision tree on top of language model outputs for multiple prompts. This gives a way to do "fine-tuning" and classify outputs without any backward passes.
iPrompt: Explaining Patterns in Data with Language Models via Interpretable Autoprompting
EMNLP 2023 BlackboxNLP [arxiv]
Chandan Singh*, John X. Morris*, Jyoti Aneja, Alexander M. Rush, Jianfeng Gao
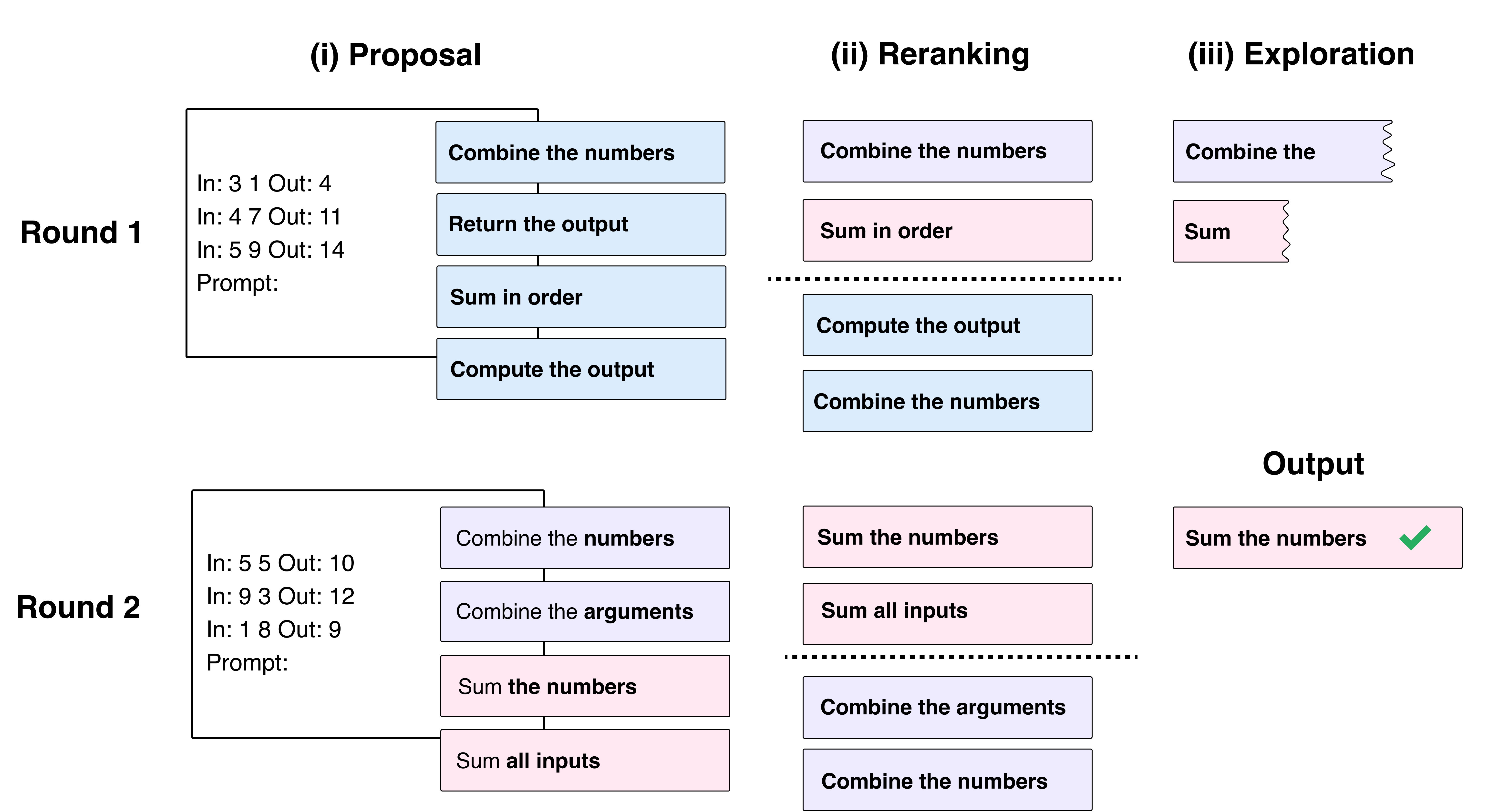
We developed a method that searches for the optimal prompt for a given dataset. It turns out that the optimal prompt is often semantically meaningful and can tell us meaningful things about the data.
Unsupervised Text Deidentification
EMNLP Findings 2022 [arxiv]
John X. Morris, Justin T. Chiu, Ramin Zabih, Alexander M. Rush
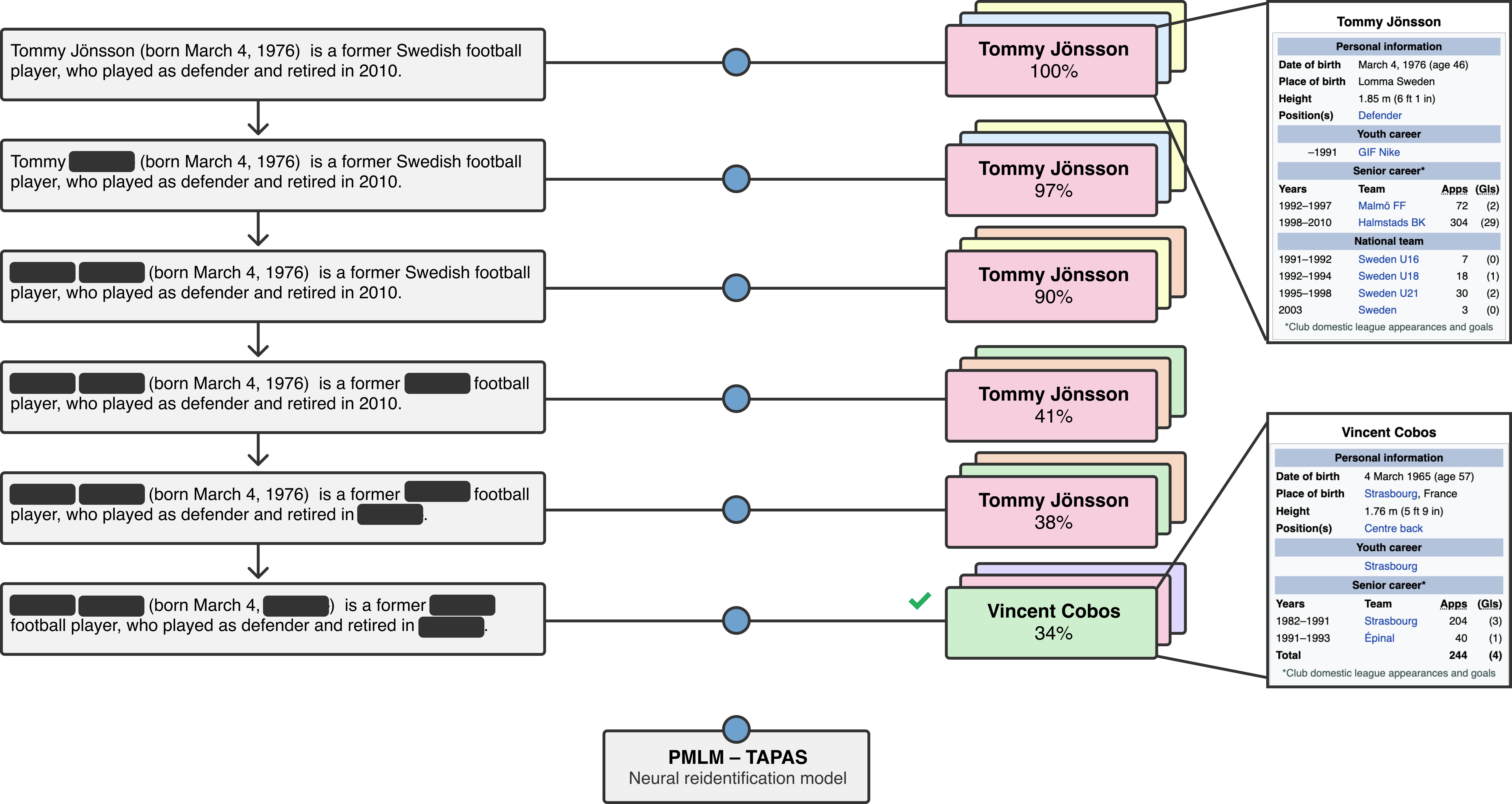
We propose a method for removing personal information from text based on the information we know about each person. We test our method by redacting biographies from Wikipedia.